1. 수직 중앙 정렬에 사용하는 방법
case 1. line-height로 부모 박스의 높이를 지정
case 2. displaydml table-cell 속성 적용 후 vertical-align 사용
case 3. position이 absolute일 경우 top: 50%; transform
<head>
<style>
* {
margin: 0;
padding: 0;
}
div {
width: 200px;
height: 100px;
border: 2px solid black;
background-color: lightgoldenrodyellow;
text-align: center; /* 수평 중앙 정렬 */
}
div.line-height {
line-height: 100px; /* 높이를 line-height로 사용 */
}
div.cell {
display: table-cell;
vertical-align: middle;
}
div.rel {
position: relative;
}
div.rel p {
position: absolute;
top: 50%;
transform: translateY(-50%);
}
</style>
</head>
<body>
<div class="line-height">vertical-align</div>
<div class="cell">vertical-align</div>
<div class="rel"><p>vertical-align</p></div>
<!-- line-height를 사용할 경우에는 요소가 한줄이어야 함 -->
<div class="inline-height">vertical-align vertical-align vertical-align</div>
</body>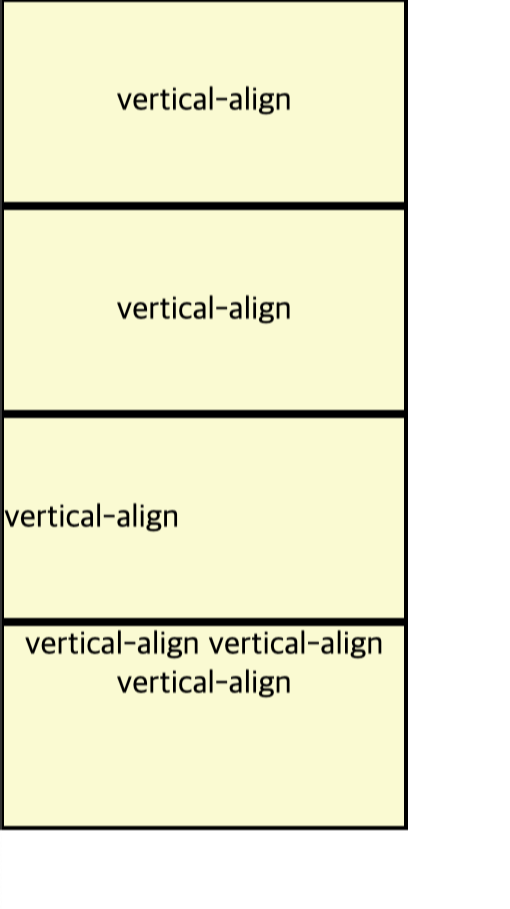
2. overflow와 scroll
1) overflow 속성
🚀 내부 요소가 부모 박스의 범위를 벗어날 때 어떻게 처리할 것인지 지정
🚀 콘텐츠가 자주 업데이트 되는 경우 높이가 콘텐츠 양에 따라 자동으로 변경이 되거나 박스의 높이를 고정값으로 할 때 사용
hidden : 영역을 벗어나는 부분은 보이지 않음
scroll : 영역을 벗어나는 부분은 스크롤 바가 나타남
visible : 박스를 넘어가도 보여줌
auto : 박스를 넘어가지 않으면 스크롤 바가 나오지 않고, 박스를 넘어갈 때 스크롤 바가 나타남
<head>
<style>
* {
margin: 0;
padding: 0;
}
.contents1 {
width: 200px;
height: 200px;
border: 2px solid black;
float: left;
box-sizing: border-box;
margin: 10px;
}
.contents2 {
width: 200px;
height: 200px;
border: 2px solid black;
float: left;
box-sizing: border-box;
margin: 10px;
margin-left: 30px; /* 왼쪽과 바깥쪽 여백을 30px로 지정함 */
}
.contents3 {
width: 200px;
overflow: hidden; /* 박스 높이가 지정되지 않았을 경우 박스 안의 내용만큼 박스 높이도 함께 늘어남 */
border: 2px solid black;
float: left;
box-sizing: border-box;
margin: 10px;
margin-left: 30px;
}
.contents4 {
width: 200px;
height: 200px;
overflow: hidden; /* 박스 높이가 지정되어있으면 지정된 높이만큼만 보여줌. */
border: 2px solid black;
float: left;
box-sizing: border-box;
margin: 10px;
margin-left: 30px;
}
</style>
</head>
<body>
<!--박스의 높이에 맞게 텍스트 양을 넣은 예-->
<div class="contents1">
<h4>콘텐츠의 양이 일정</h4>
<p>Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown </p>
</div>
<!--박스의 높이보다 텍스트의 양이 많아서 박스 밖으로 흘러넘치는 예-->
<div class="contents2">
<h4>콘텐츠의 양이 많거나 유동적일때 흘러 넘침</h4>
<p>Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged.</p>
</div>
<!--박스의 높이를 설정하지 않고 overflow:hidden을 지정하여 텍스트만큼 높이도 함께 늘어나는 예-->
<div class="contents3">
<h4>콘텐츠의 양에 따라서 높이가 늘어남</h4>
<p>Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged.</p>
</div>
<!--박스의 높이를 지정하고 overflow:hidden을 주어서 높이만큼만 보여지도록 한 예-->
<div class="contents4">
<h4>박스의 지정된 높이만큼만 콘텐츠가 보여짐</h4>
<p>Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged.</p>
</div>
</body>

2) scroll 속성
🚀 overflow: scroll 속성 사용
▶️ 박스(block)의 내부 스크롤 바를 지정하고자 할 때 사용
overflow : 영역을 벗어나는 가로, 세로 부분을 스크롤 바로 나타나게 하거나 숨김
overflow-x : 가로 좌표에 대한 스크롤 바를 나타나게 하거나 숨김
overflow-y : 세로 좌표에 대한 스크롤 바를 나타나게 하거나 숨김
<head>
<style>
* {
margin: 0;
padding: 0;
}
.scroll_box1 {
float: left;
box-sizing: border-box;
width: 200px;
height: 200px;
border: 2px solid black;
margin: 10px;
overflow: scroll; /* 가로 세로 스크롤 바를 모두 보임 */
}
.scroll_box2 {
float: left;
box-sizing: border-box;
width: 200px;
height: 200px;
border: 2px solid black;
margin: 10px;
margin-left: 30px; /* 왼쪽 바깥쪽 여백은 30px로 지정함 */
overflow-x: scroll; /* 가로 스크롤 바를 표시 */
overflow-y: hidden; /* 세로 스크롤 바를 숨김 */
}
.scroll_box3 {
float: left;
box-sizing: border-box;
width: 200px;
height: 200px;
border: 2px solid black;
margin: 10px;
margin-left: 30px; /* 왼쪽 바깥쪽 여백은 30px로 지정함 */
overflow-x: hidden; /* 가로 스크롤 바를 숨김 */
overflow-y: scroll; /* 세로 스크롤 바를 표시 */
}
</style>
</head>
<body>
<!-- 스크롤 바를 가로, 세로 모두 표시 -->
<div class="scroll_box1">
<h4>SCROLL-X,Y</h4>
<p><img src="../box2/img2/camera02.png" alt="대체이미지"></p>
</div>
<!-- 스크롤 바를 가로만 표시 -->
<div class="scroll_box2">
<h4>SCROLL-X</h4>
<p><img src="../box2/img2/camera02.png" alt="대체이미지"></p>
</div>
<!-- 스크롤 바를 세로만 표시 -->
<div class="scroll_box3">
<h4>SCROLL-Y</h4>
<p><img src="../box2/img2/camera02.png" alt="대체이미지"></p>
</div>
</body>

[ 내용 참고: IT 학원 강의 ]
'HTML&CSS > CSS' 카테고리의 다른 글
| [CSS] 배경 이미지 지정과 속성 (0) | 2024.03.22 |
|---|---|
| [CSS] 고급 선택자 | 연결 선택자, 속성 선택자, 가상 클래스와 가상 요소 (0) | 2024.03.21 |
| [CSS] display 속성과 사용 예, float, clear, 여백 조절-[margin, padding] (0) | 2024.03.20 |
| [CSS] 박스 모델 요소 및 구성, 테두리 스타일 지정 (0) | 2024.03.20 |
| [CSS] CSS 스타일, 기본 선택자, 캐스케이딩 스타일 시트 (0) | 2024.03.19 |