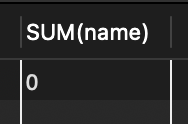
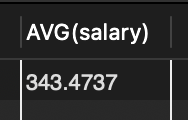
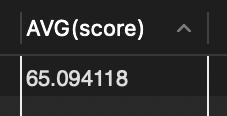
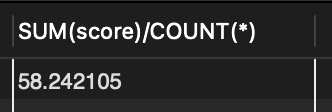
1. DELETE
DELETE FROM 테이블 WHERE 조건 ;👩🏻💻 레코드를 삭제할 때 사용한다.
👩🏻💻 삭제는 항상 레코드 단위로 수행하므로 필드에 대한 지정은 없음.
👩🏻💻 삭제 동작은 특정 조건에 맞는 레코드를 찾아 제거하는 경우가 대부분이어서 WHERE 절이 항상 뒤따라 온다.
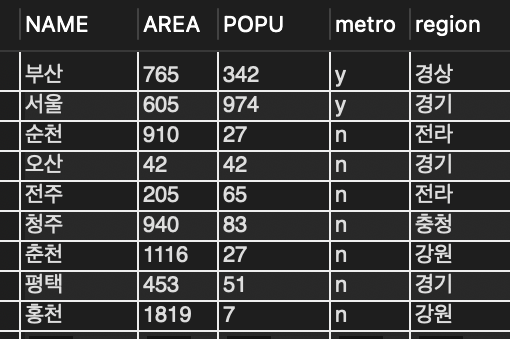
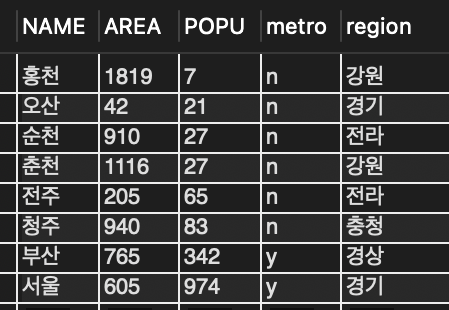
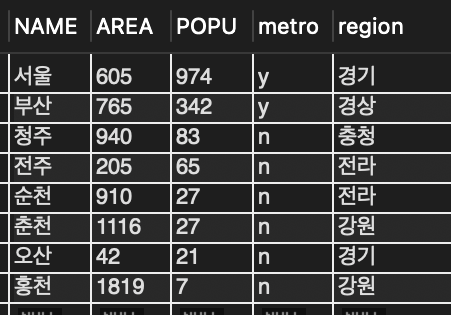
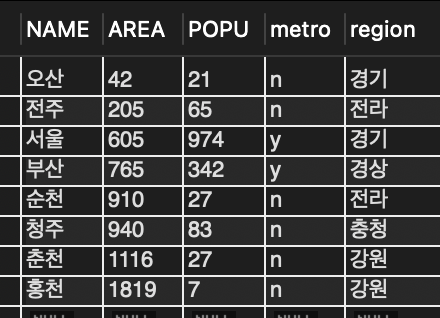
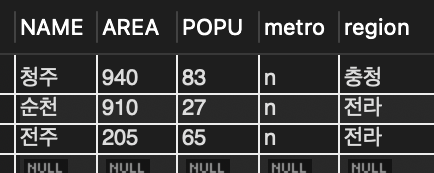
DELETE FROM tCity WHERE name = '부산';
SELECT * FROM tCity;
⬇️
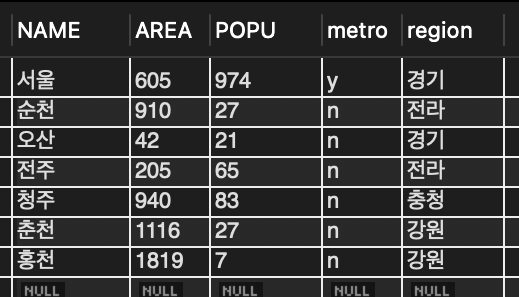
📌 도시명이 '부산'인 레코드를 삭제
2. 삭제 안전 장치
👩🏻💻 삭제시 문제가 되는 부분은 1) 조건절을 빼거나 2) 잘못된 조건을 사용하는 경우
👩🏻💻 조회만 하는 SELECT 명령은 테이블을 변경하지 않아 실수해도 조건을 바꿔 다시 조회하면 됨.
INSERT 명령은 테이블을 변경하지만 혹시라도 잘못 삽입했으면 다시 지우면 되어서 그다지 위험하지 않음
하지만 잘못 내린 DELETE 명령은 즉시처리해 버림.
👩🏻💻 DELETE문은 특정 레코드를 삭제하기 위해 WHERE 절과 함께 사용하지만 실수로 WHERE 절을 생략해 버리면 모든 데이터가 삭제됨
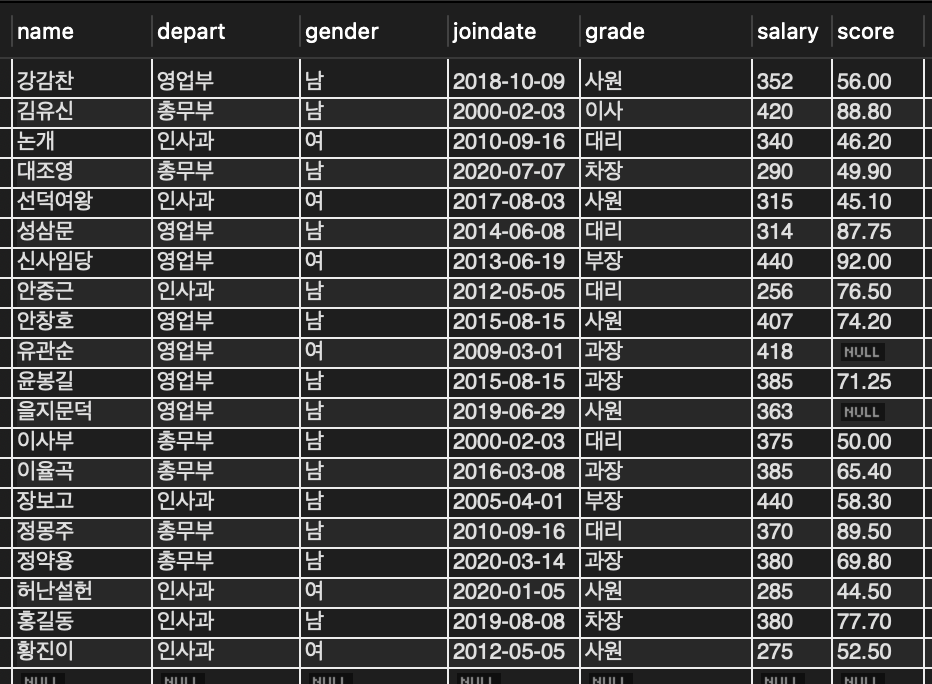
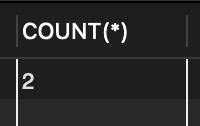
📌 만일 월급이 300 초과인 직원을 삭제한다면 다음 절차대로 작업
// 1. DELETE 명령을 내리기 전에 먼저 SELECT로 삭제 대상 레코드를 고름
SELECT * FROM tStaff WHERE salary > 300;
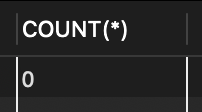
// 2. 조건을 맞는지 확인 후 제거
DELETE FROM tStaff WHERE salary > 300;
3. TRUNCATE
TRUNCATE TABLE 테이블 ;👩🏻💻 테이블 초기화 할 때 쓰는 명령어
👩🏻💻 DELETE 명령은 수십만건의 레코드를 일일이 지우게 되면 서버에 부하가 생긴다.
➡️ 이 경우 TRUNCATE 명령을 사용하는 것이 효율적
➡️ 물리적인 기억 장소를 깨끗이 비우고 임시 영역에 로그도 남기지 않아 훨씬 빠르다
TRUNCATE TABLE tCity;
🔽

[ 내용 참고 : IT 학원 강의 ]
'Database > MySQL' 카테고리의 다른 글
| [MySQL] 서브쿼리 (SubQuery) (1) | 2024.02.24 |
|---|---|
| [MySQL] UPDATE 문 (1) | 2024.02.24 |
| [MySQL] INSERT 문 (0) | 2024.02.23 |
| [MySQL] GROUP BY, HAVING (0) | 2024.02.23 |
| [MySQL] 집계 함수 (aggregate function) (0) | 2024.02.23 |