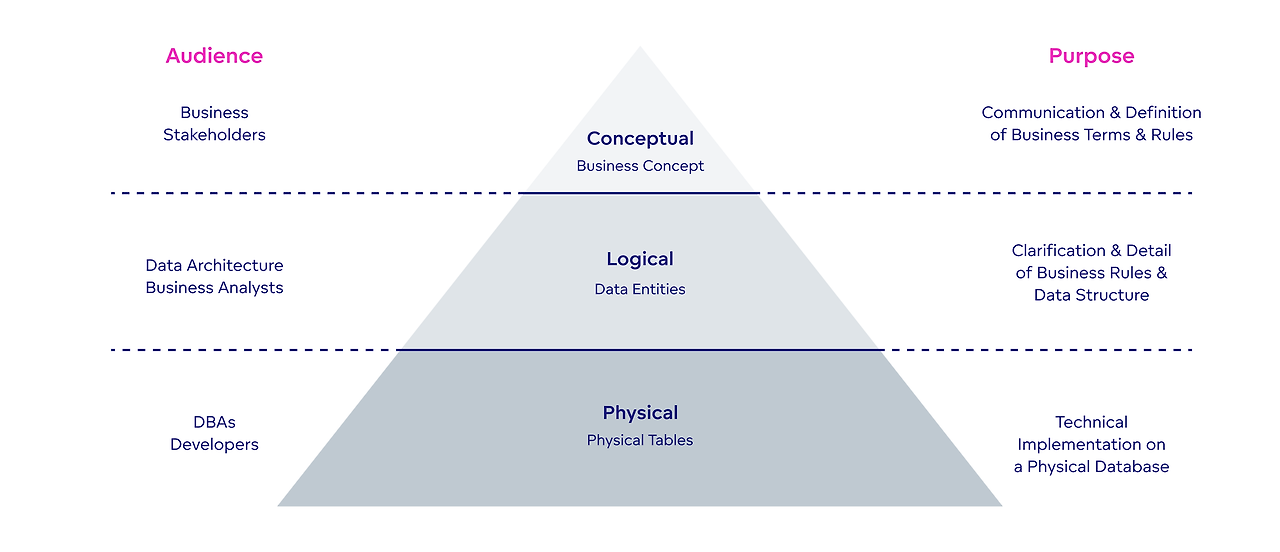
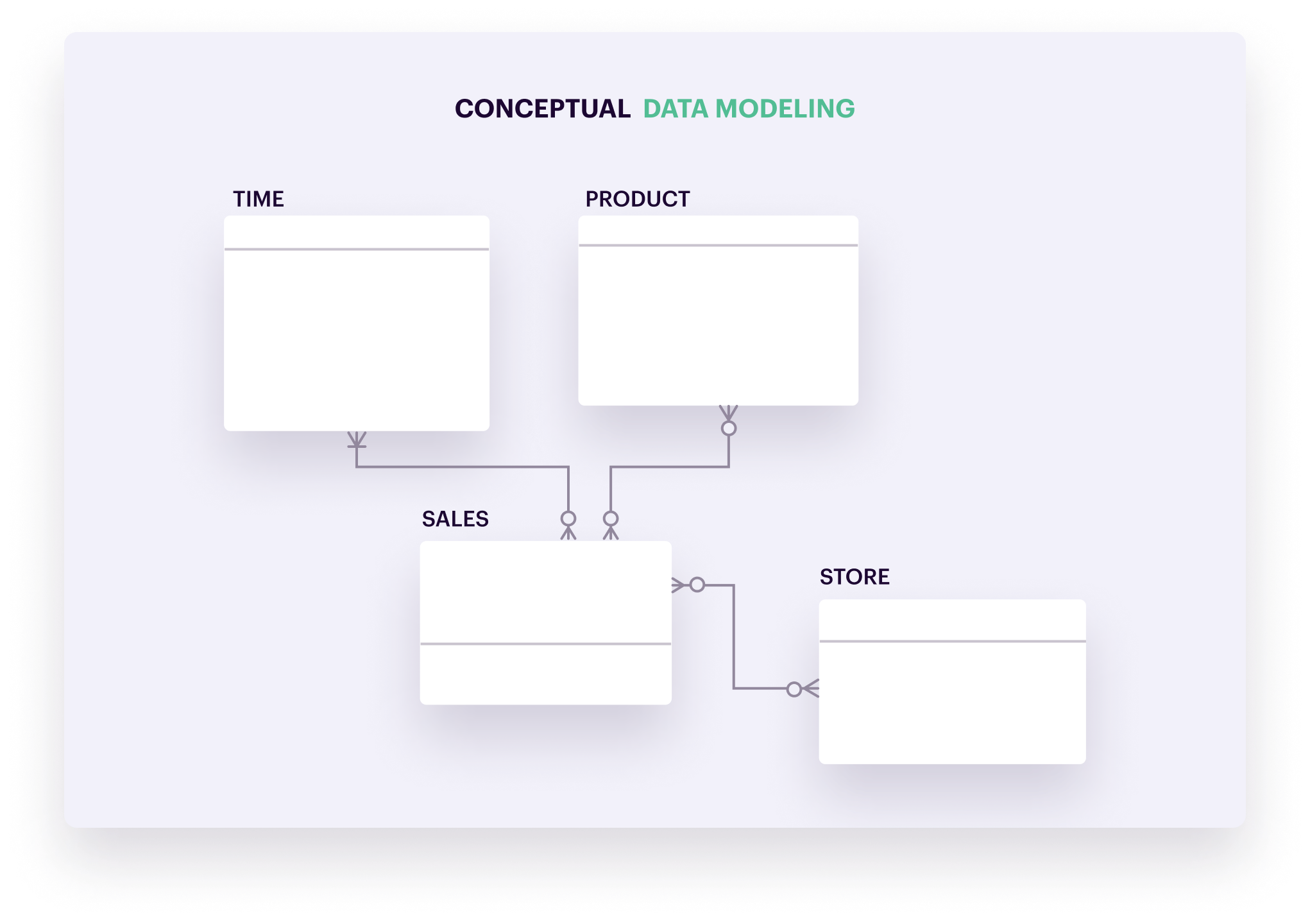
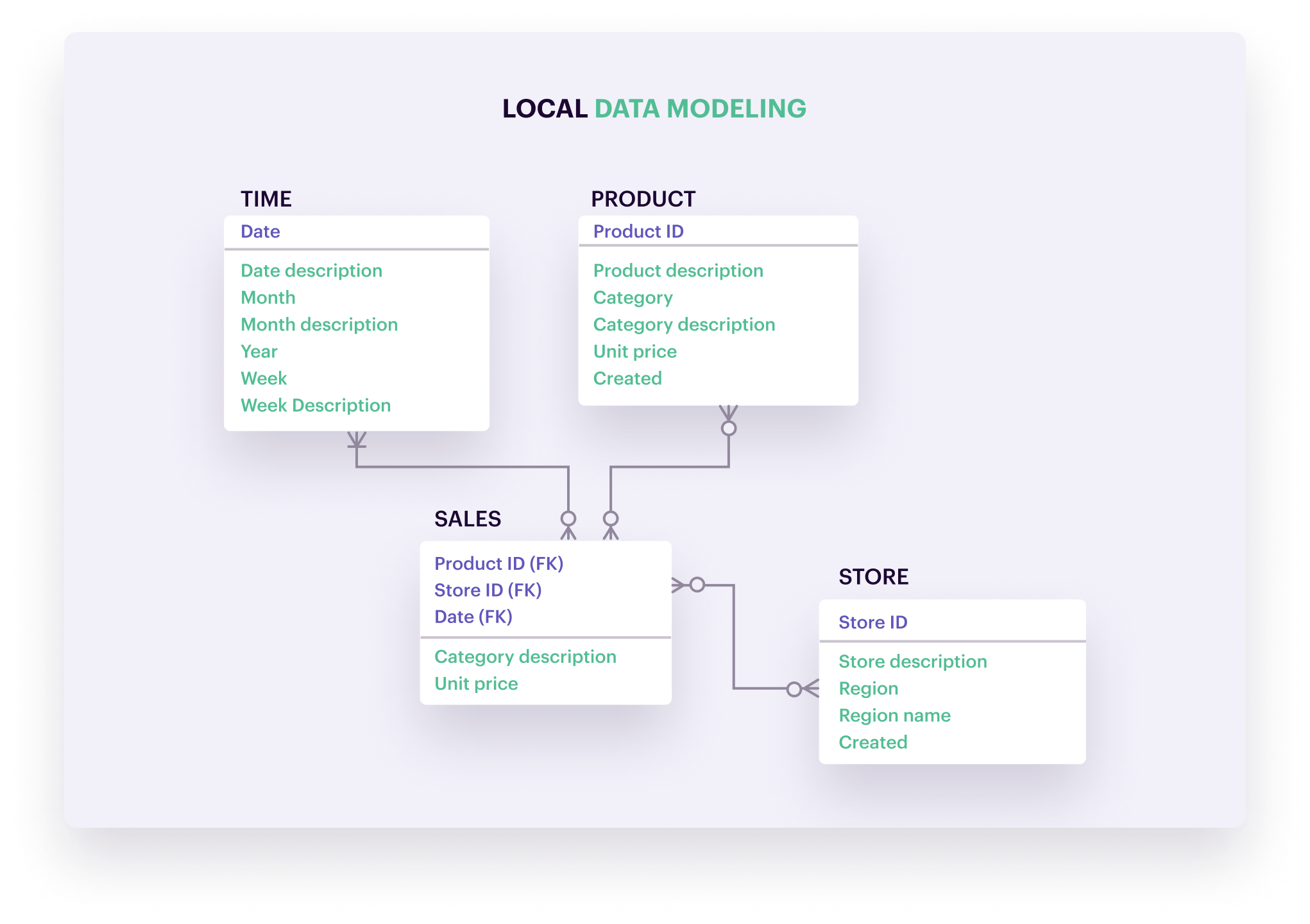
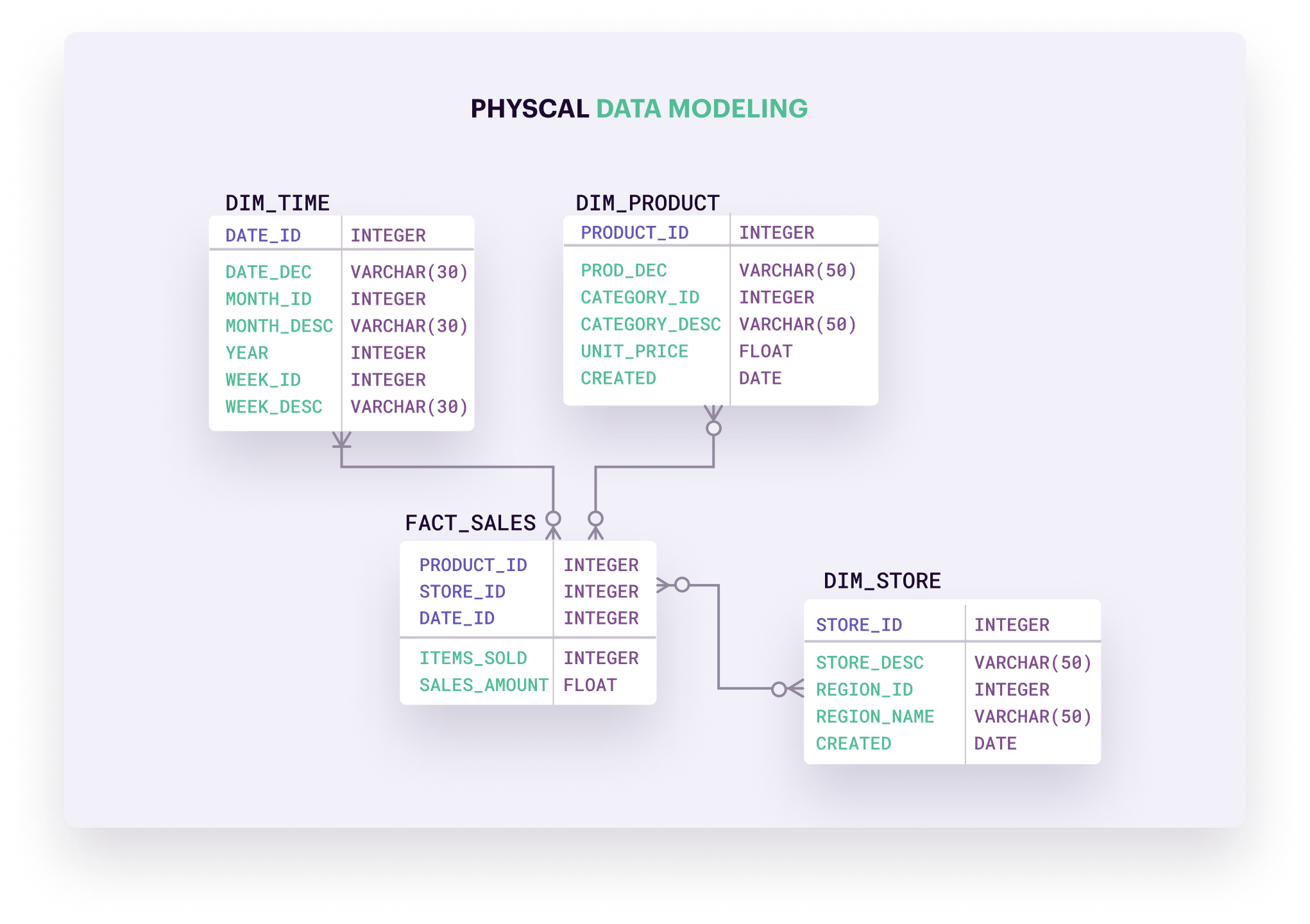
1. 참조 무결성
1) 참조 관계
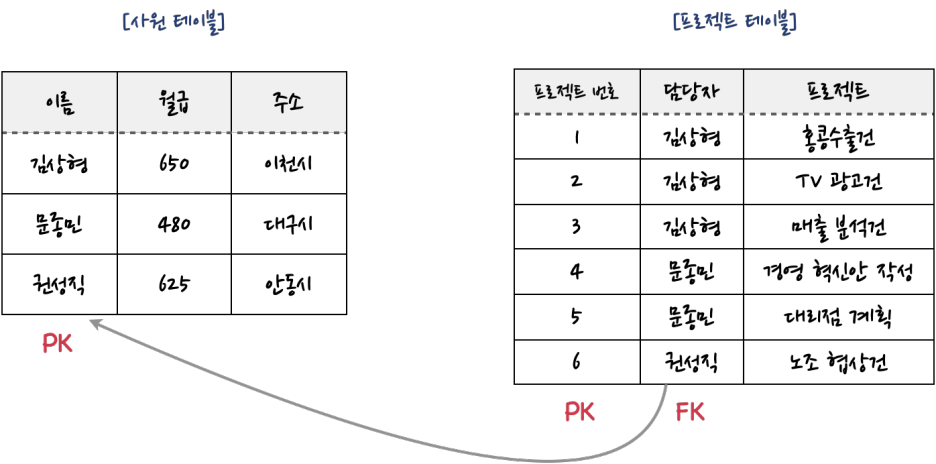
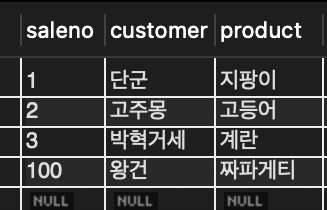
👩🏻🚀 제 1 정규화에서 예로 들었던 직원과 프로젝트 테이블을 생성하고 관계를 맺는다
➡️ 두 개의 테이블을 만들되 프로젝트에 비용 필드를 추가
📌 먼저 부모 테이블에 해당하는 직원 테이블을 생성하고 샘플 데이터를 입력
CREATE TABLE `tEmployee`
(
`name` CHAR(10) PRIMARY KEY, // 직원의 이름을 기본키로 지정
`salary` INT NOT NULL, // 월급
`addr` VARCHAR(30) NOT NULL // 주소
);
INSERT INTO `tEmployee` VALUES ('김상형', 650, '이천시');
INSERT INTO `tEmployee` VALUES ('문종민', 480, '대구시');
INSERT INTO `tEmployee` VALUES ('권성직', 625, '안동시');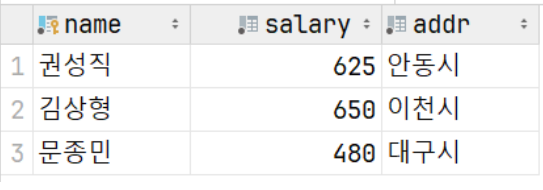
📌 다음은 직원 테이블과 관계를 맺을 프로젝트 테이블을 생성
CREATE TABLE `tProject`
(
`projectID` INT PRIMARY KEY, --기본키인 projectID는 자동 증가열로 정의하는 것이 간편
`employee` CHAR(10) NOT NULL, --담당자
`project` VARCHAR(30) NOT NULL, --프로젝트이름
`cost` INT --비용
);
INSERT INTO `tProject` VALUES (1, '김상형', '홍콩 수출건', 800);
INSERT INTO `tProject` VALUES (2, '김상형', 'TV 광고건', 3400);
INSERT INTO `tProject` VALUES (3, '김상형', '매출분석건', 200);
INSERT INTO `tProject` VALUES (4, '문종민', '경영 혁신안 작성', 120);
INSERT INTO `tProject` VALUES (5, '문종민', '대리점 계획', 85);
INSERT INTO `tProject` VALUES (6, '권성직', '노조 협상건', 24);
👾 employee 외래키는 직원 테이블의 name키를 가리키며 이 관계를 통해 프로젝트의 담당자가 누구인지 알 수 있음
💡 두 테이블은 담당한다는 관계 = (참조)를 맺음
* 참고 *
- 테이블 이름은 표현하는 엔티티로 붙이는 것이 좋음
➡️ 도시의 정보를 다루니 tCity로 이름을 붙이고 직원 목록은 tStaff으로 붙임 프로젝트명은 tProject가 어울림.
- 레코드 여러 개를 저장한다고 해서 굳이 복수형으로 작성할 필요는 없음
➡️ tCities, tStaffs, tProjects로 해도 문제는 없지만 테이블에는 어차피 여러 개의 레코드가 들어가니 복수형일 필요 없음
2) 외래키 제약
👩🏻💻 직원과 프로젝트의 샘플 데이터는 규칙에 맞게 입력하여 참조 관계가 정확
📌 새로 레코드를 삽입할 때는 아직 문제가 있음
INSERT INTO `tProject` VALUES (7, '홍길동', '원자재 매입', 900);👾 새로운 프로젝트의 담당자로 지정한 '홍길동'은 직원 테이블에 존재하지 않음
👾 외래키가 존재하지 않는 잘못된 키를 가리키고 있지만 이상 없이 잘 삽입됨
📌 다음 명령도 문제가 있음
DELETE FROM `tEmployee` WHERE name = '김상형';👾 이 명령은 '김상형' 직원을 삭제
➡️ 이 직원이 맡고 있는 모든 프로젝트는 담당자를 잃어버림.
👾 외래키가 가리키는 대상이 사라져 참조 무결성이 깨져 버림
👾 관계를 기반으로 동작하는 RDB의 참조 무결성이 깨지면 이후의 동작을 보증할 수 없음
👩🏻💻 DB 엔진은 시키는대로 할 뿐 실행을 거부할 이유 x ➡️ 이런 이유로 외래키(FK) 제약이 필요
👩🏻💻 외래키 제약은 어떤 필드가 외래키인지, 어떤 테이블의 무슨 키를 참조하는지 지정
👩🏻💻 외래키 제약이 있으면 참조 무결성이 깨지는 명령의 실행을 거부
📌 직원 테이블은 원상 복구해 두고 tProject 테이블은 다시 정의
CREATE TABLE `tProject` (
`projectID` INT PRIMARY KEY,
`employee` CHAR(10) NOT NULL,
`project` VARCHAR(30) NOT NULL,
`cost` INT,
CONSTRAINT FK_emp FOREIGN KEY(`employee`) REFERENCES `tEmployee`(name`)
// 마지막 필드 끝에 콤마를 찍고 제일 아래에 외래키 제약을 추가
);
👾 제약의 이름과 종류를 지정하고 REFERENCES 키워드 다음에 테이블(필드) 형식으로 참조하는 테이블과 키를 지정
👾 오라클과 SQL Server는 외래키 필드 선언문에 컬럼 제약으로 지정할 수도 있음
`employee` ...CHAR(10) NOT NULL REFERENCES
`tEmployee`(name),👾 외래키 제약은 employee 필드가 tEmployee 테이블의 name 필드와 연결되었음을 선언
➡️ 이후 DBMS는 이 제약을 위반하는 모든 명령의 실행을 거부
INSERT INTO `tProject` VALUES (7, '홍길동', '원자재 매입', 900);
// ORA-02291: 무결성 제약조건(SYSTEM.FK_EMP)이 위배되었습니다- 부모 키가 없습니다DELETE FROM `tEmployee` WHERE `name` = '김상형';
// ORA-02292: 무결성 제약조건(SYSTEM.FK_EMP)이 위배되었습니다- 자식 레코드가 발견되었습니다💡 둘 다 에러 메시지를 출력하고 실행을 거부
➡️ 원하는대로 하려면 다음 두 명령을 순서대로 실행
INSERT INTO `tEmployee` VALUES ('홍길동', 330, '장성');
INSERT INTO `tProject` VALUES (7, '홍길동', '원자재 매입', 900);💡 직원을 먼저 등록해야 이 직원에게 프로젝트를 맡길 수 있음
➡️ 마찬가지로 직원을 삭제하려면 다음 두 명령을 순서대로 실행
DELETE FROM `tProject` WHERE `employee` = '김상형';
DELETE FROM `tEmployee` WHERE `name` = '김상형';💡 직원이 맡고 있는 프로제트를 모두 제거하거나 아니면 다른 직원에게 넘겨야 이 직원을 컷할 수 있음
📌 FK 제약이 설정되어 있는 상태에서 다음 쿼리문도 에러 처리
DROP TABLE `tEmployee`;👾 직원 테이블을 삭제하면 프로젝트 테이블 전체가 무효해짐
➡️ 정직원 테이블을 삭제하려면 프로젝트 테이블부터 비워야 함
👩🏻💻 DBMS가 외래키 제약에 대한 규칙을 정확하게 알고 있으므로 무결성을 해치는 모든 명령을 원천적으로 차단
👩🏻💻 외래키 제약은 참조 무결성을 지키는 강력한 수단
3) 연계 참조 무결성 제약
👩🏻🚀 외래키 제약관련 작업을 자동화하여 한 번에 처리하는 연계 참조 무결성 제약
👩🏻🚀 관련키의 삭제나 수정을 무조건 금지하는 것이 아니라 추가 동작까지 자동으로 처리하여 무결성을 유지하는 기능
👩🏻🚀 부모 테이블을 변경하면 자식 테이블까지 알아서 수정
💡 이 기능을 사용하려면 외래키 제약 뒤에 다음 선언을 추가
ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }👾 ON DELETE는 참조되는 키가 삭제될 때의 동작을 정의하며 ON UPDATE는 참조되는 키가 변경될 때의 동작을 정의
📌 각각에 대해 4개의 옵션을 지정할 수 있음
* NO ACTION은 아무것도 하지 않고 실패하도록 내버려 두는 것이며 이 옵션이 디폴트
* CASCADE는 참조되는 키와 연결되어 있는 외래키를 자동으로 삭제하거나 변경
* SET NULL이나 SET DEFAULT는 외래키를 NULL이나 기본값으로 변경하는데 외래키가 NULL 허용이거나 기본값이 지정되어 있어야 함
📌 tProject 테이블을 삭제한 후 다음 명령으로 다시 생성
CREATE TABLE `tProject` (
`projectID` INT PRIMARY KEY,
`employee` CHAR(10) NOT NULL,
`project` VARCHAR(30) NOT NULL,
`cost` INT,
CONSTRAINT FK_emp FOREIGN KEY(`employee`) REFERENCES `tEmployee`
ON DELETE CASCADE
);
👾 ON DELETE에 대해 CASCADE 옵션을 지정하여 필요한 추가 처리를 자동으로 하도록 함
👾 이 상태에서 다음 명령으로 직원을 삭제
DELETE FROM `tEmployee` WHERE `name` = '김상형';💡 외래키 제약만 걸려 있다면 이 명령은 당연히 에러지만 CASCADE 옵션이 지정되어 있어 에러 없이 실행 가능
📌 실행하기 전 후 차이
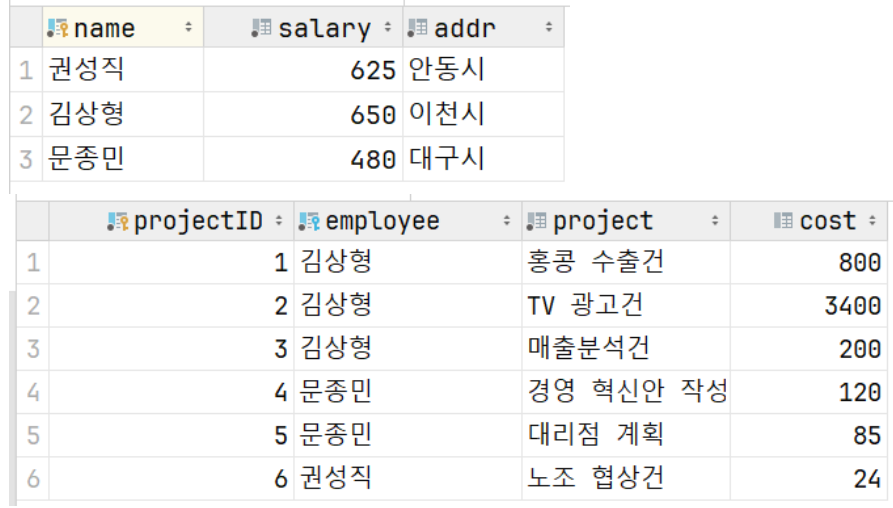
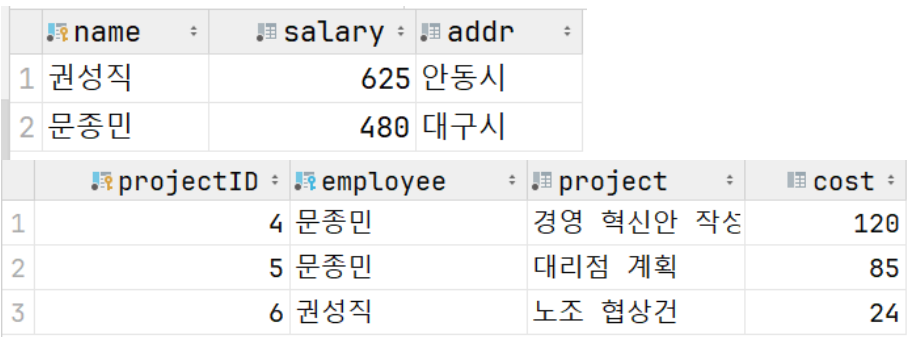
👾 직원 뿐만 아니라 tProject에 이 직원이 담당한 프로젝트도 같이 삭제
👾 연계 참조란 이런 식으로 하나를 삭제하면 연결된 다른 테이블을 자동으로 수정하는 기능
💡 만약 연계에 의해 삭제되는 레코드에 또 다른 연계 참조 무결성 제약이 걸려 있다면 연쇄적으로 수정
👾 ON UPDATE 선언을 하면 참조키 수정시 관련 외래키를 같이 수정하며 동작 방식은 ON DELETE와 유사
👾 SQL Server와 MariaDB는 이 기능을 지원하지만 오라클은 ON DELETE까지만 지원하며 똑같은 기능을 구현하려면 트리거를 사용해야 함
📌 tProject 테이블을 삭제한 후 다음 명령으로 다시 생성
📌 ON DELETE와 ON UPDATE에 대해 모두 CASCADE 동작을 지정
CREATE TABLE `tProject`(
`projectID` INT PRIMARY KEY,
`employee` CHAR(10) NOT NULL,
`project` VARCHAR(30) NOT NULL,
`cost` INT,
CONSTRAINT FK_emp FOREIGN KEY(`employee`) REFERENCES `tEmployee`
ON DELETE CASCADE ON UPDATE CASCADE
);👾 직원을 삭제하면 연관 정보도 같이 삭제
📌 이번에는 직원이 이름을 변경한 상황을 가정하여 UPDATE 명령으로 참조키를 수정
`tEmployee` SET `name` = '문사장' WHERE `name` = '문종민';👾 이름이 바뀌는 것은 원래의 이름이 없어지는 것과 같아 프로젝트의 담당자가 무효해짐
👾 외래키 제약만 걸려 있다면 담당자의 이름만 바꾸는 것은 불가능
👾 연계 참조 무결성 제약이 걸려 있으면 참조되는 키를 수정할 수 있음
➡️ 직원 이름을 수정하면 tProject의 외래키도 같이 변경
➡️ 담당자의 이름과 프로젝트의 담당자가 동시에 바뀌므로 무결성은 여전히 유지
💡 자동으로 처리한다는 면에서 편리하지만 이 기능은 함부로 사용 x, 실무에서도 잘 사용하지 않음
[ 내용 참조 : IT 학원 강의 ]
'Database > MySQL' 카테고리의 다른 글
| [MySQL] JDBC 예제 (0) | 2024.02.25 |
|---|---|
| [MySQL] JDBC 정의, 로딩, 프로그램 개발 절차 (0) | 2024.02.25 |
| [MySQL] 데이터베이스 모델링 | 1~3 정규화, 역정규화 (1) | 2024.02.25 |
| [MySQL] 데이터베이스 모델링 | 진행단계, 분류, 엔티티, 관계 (0) | 2024.02.25 |
| [MySQL] 제약조건 | 일련번호, 시퀀스, AUTO_INCREMENT (0) | 2024.02.24 |