1. 단일행 서브쿼리
💡 서브쿼리란? 쿼리문 안에 또 쿼리문이 들어 있는 것
💡 서브쿼리는 다른 쿼리문안에 내장되어 있는 SELECT 문이며 연속적으로 실행할 쿼리를 하나로 합침
💡 SELECT로 할 수 있는 질문은 짧은 단문만 가능, FROM 절이 하나밖에 없어 한 테이블에 있는 정보만 조사할 수 있다.
➡️ 실제 작업을 할때는 복잡한 여러 단계의 질문을 한꺼번에 하는 경우가 많이 생김.
➡️ 복잡한 쿼리를 실행할 수 있는 방법이 바로 서브쿼리.
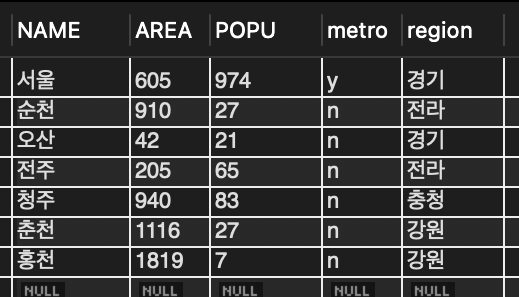
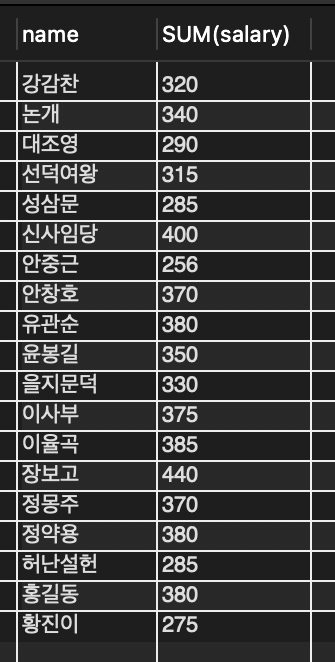
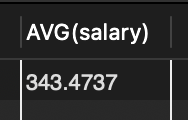
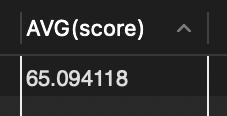
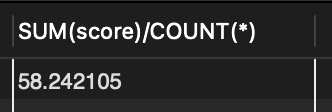
SELECT MAX(popu), name FROM tCity;📖 최대 인구수를 가진 도시를 구하는 문제
🔎 MAX 함수의 결과는 집계한 하나의 값이고 name 필드는 도시명 여러 개여서 이 둘을 같이 출력 불가
🔎 MAX(popu)는 최대 인구수를 집계한 것이 맞지만 name 도시중 어떤 도시가 그 인구수를 가진 것인지는 알 수 없음.
➡️ 즉, 왼쪽 열과 오른쪽 열이 연관성이 없음.
📖 기계가 이 명령을 알아 들으려면 문법적으로 가능한 질문을 순서대로 해야 한다.
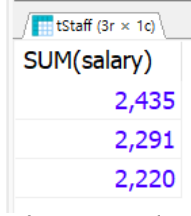
SELECT MAX(popu) FROM tCity; // 974
1. 전체 도시의 인구 중 가장 큰 값을 조사
SELECT name FROM tCity WHERE popu = 974;2. 이 인구수를 가진 도시를 찾음
📖 최대 인구수를 조사하고 이 수로부터 도시의 이름을 구해야 하니 두 번의 쿼리가 필요
➡️ 두 개의 쿼리를 하나로 묶어 실행할 때 쓰는 것이 서브쿼리
💡 이 때 서브쿼리를 감싸는 전체 쿼리를 외부쿼리라 부름
➡️ 외부쿼리와 구분하고 실행 순서를 명확히 지정하기 위해 서브쿼리를 괄호로 감쌈
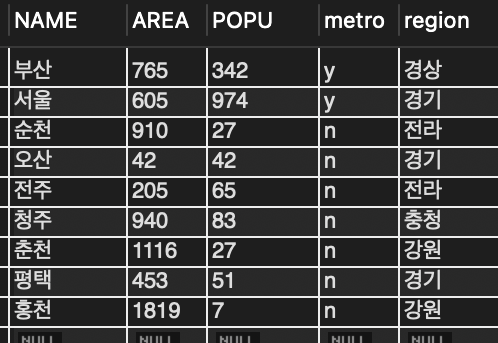
SELECT name FROM tCity WHERE popu = (SELECT MAX(popu) FROM tCity);📖 서브쿼리로 최대 인구수를 가진 도시명을 구함
1. 괄호 안의 서브쿼리를 먼저 실행하여 최대 인구수를 구함.
2. 서브쿼리를 포함하고 있는 외부쿼리를 실행하여 popu가 서브쿼리가 구한 최대 인구수와 같은 도시를 조사하여 출력.
💡 단일행 서브쿼리는 하나의 결과만 리턴하며 주로 WHERE, HAVING 등의 조건절에 사용
💡 복합 질문의 앞쪽 질문에 해당하는 값을 서브 쿼리로 조사해 놓고 외부쿼리에서 그 결과값을 사용하는 식으로 작성한다.
2. 서브쿼리 중첩
💡 서브쿼리는 독립적인 하나의 명령이기 때문에 외부쿼리와는 '다른 테이블을 읽을 수도 있음'
💡 순차적으로 실행되므로 두 쿼리문의 FROM 절에 각각 다른 테이블을 지정해도 된다.
// 청바지 배송비가 얼마인지 조사
// 청바지는 상품 테이블 tItem 에 있지만 배송비는 유형 테이블 tCategory에 있어서 두 테이블을 읽어야 함
// 먼저 tItem 테이블에서 청바지는 어떤 유형의 상품인지 조사
SELECT category FROM tItem WHERE item= '청바지';
// 청바지는 '패션' 유형. 다음은 패션 유형의 배송비를 조사.
SELECT delivery FROM tCategory WHERE category = '패션';
// 배송비는 2,000원. 이제 둘을 하나로 합침.
// WHERE 절의 '패션' 자리에 상수 대신 '패션'이라는 결과를 만들어 내는 서브쿼리를 작성하고 괄호를 둘러쌈
SELECT delivery FROM tCategory WHERE category =
(SELECT category FROM tItem WHERE item = '청바지');💡 서브쿼리의 중첩 횟수에는 제약이 없어 서브쿼리내에 또 다른 서브쿼리를 포함할 수 있음
💡 리턴 값이 여러 개면 에러 처리되는데 이때는 TOP 1 (LIMIT 1) 을 넣어 첫 해당 값을 찾으면 된다.
3. 다중행 서브쿼리
💡 서브쿼리의 '결과가 하나뿐인 유형'을 단일행 서브쿼리
➡️ 단일값이므로 조건절에서 =, <, > 등의 비교 연산자와 함께 사용할 수 있음.
➡️ 비교 연산자는 필드의 값과 비교하는 것이어서 '우변이 반드시 하나의 확정된 값'이어야함.
💡 이에 비해 여러 행을 리턴하는 것이 다중행 서브쿼리
➡️ 단일값이 아닌 목록을 리턴하기 때문에 값끼리 비교하는 비교 연산자와 함께 사용할 수 없음
// 다음 쿼리문은 문법에는 이상이 없지만 데이터가 조건에 맞지 않아 에러 처리.
SELECT price FROM tItem WHERE item =
(SELECT item FROM tOrder WHERE member = '향단');📖 서브쿼리는 구입목록인 tOrder 테이블에서 향단이가 뭘 샀는지 조사
➡️ 안쪽 서브쿼리만 실행해 보면 향단이가 산 것은 대추와 사과 2개
➡️ = 연산자는 필드값을 두 개의 결과와 비교할 수 없어 다음 에러를 출력.
[21000][1242] (conn=327) Subquery returns more than 1 row📖 ' = '연산자로 비교하려면 조건절의 쿼리문은 반드시 하나의 단일 값을 리턴해야만 한다.
📖 꼭 조사하려면 결과 셋 중 하나의 값만 조사해서 비교하면 됨
SELECT price FROM tItem WHERE item =
(SELECT item FROM tOrder WHERE member = '향단'
ORDER BY item LIMIT 0, 1);📖 구입한 상품 중 하나의 상품만 리턴하면 = 연산자로 비교할 수 있음.
📖 그러나 질문대로 향단이가 구입한 모든 상품의 가격을 알고 싶다면 IN 연산자를 사용
SELECT item, price FROM tItem WHERE item IN
(SELECT item FROM tOrder WHERE member = '향단');💡 IN은 = 과 달리 여러 개의 값과 비교
📌 서브쿼리가 두 개 이상의 값을 리턴하면 결과셋을 괄호 안에 나열하며 IN 연산자는 이 값을 순서대로 비교
// 서브쿼리까지 실행한 직후의 외부쿼리는 다음과 같음.
// 2개의 상품에 대해 이름과 가격을 같이 출력.
SELECT item, price FROM tItem WHERE item IN ('대추', '사과');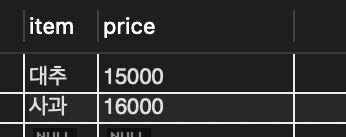
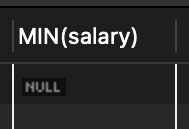
💡 결과가 없으면 NULL을 리턴하며 조건절에서 필드와 NULL을 비교하는 것은 문법적으로 가능.
➡️ 아무 결과셋도 출력하지 않을 뿐 에러는 아니다.
4. 다중열 서브쿼리
💡 단일행, 다중행 서브쿼리는 '결과셋의 컬럼이 하나'밖에 없으며 그래서 특정값과 비교할 수 있음.
💡 다중열 서브쿼리는 결과셋의 컬럼이 여러 개이며 한꺼번에 여러 값과 비교
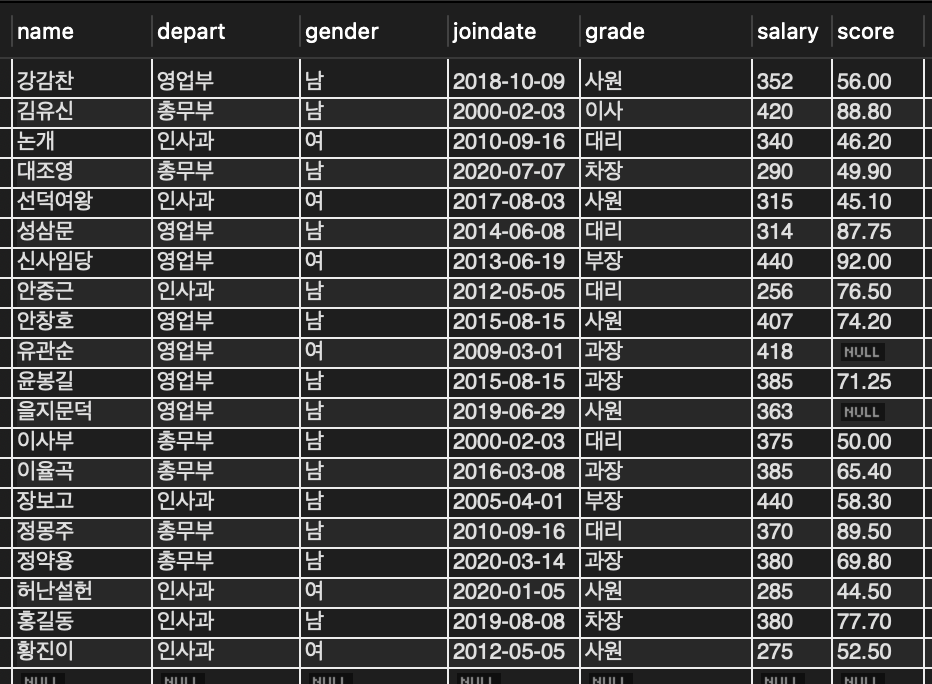
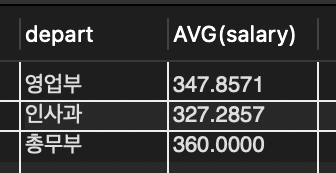
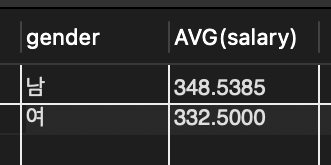
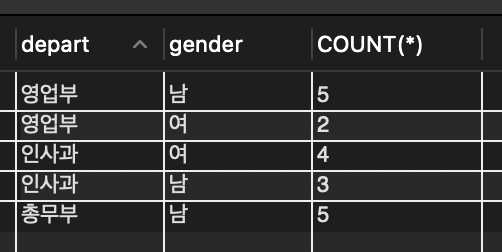
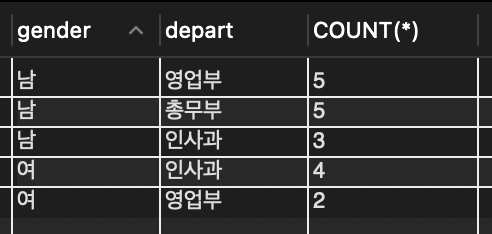
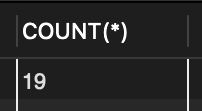
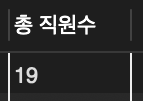
📌 윤봉길과 같은 부서에 근무하는 같은 성별의 직원 목록을 조사
📌 먼저 윤봉길이 어느 부서에 근무하고 성별이 무엇인지 조사해야 하며 그 결과로부터 조건에 맞는 직원을 찾는다
SELECT depart, gender FROM tStaff WHERE name = '윤봉길'; // 윤봉길 영업부에 근무하는 남자 직원
SELECT * FROM tStaff WHERE depart = '영업부' AND gender = '남'; // 조건에 맞는 직원 목록을 조사
🔎 윤봉길 자신까지 포함하여 5명의 직원이 있음
🔎 임의의 직원에 대해 똑같은 조사를 하려면 두 번 손이 가게 되어서 번거로움
➡️ 조사 후 조건에 맞는 목록 출력까지 한 번에 수행하는 서브쿼리가 필요
💡 다중열 서브쿼리를 사용하면 두 개의 컬럼을 리턴한 후 한꺼번에 비교
SELECT * FROM tStaff WHERE (depart, gender) =
(SELECT depart, gender FROM tStaff WHERE name = '윤봉길');📌 WHERE 절에 비교 대상 필드를 괄호 안에 (depart, gender) 적으면 서브쿼리의 컬럼과 1:1로 비교하여 두 필드가 일치하는 레코드를 검색
📌 단 일괄 비교가 성립하려면 비교 대상과 서브쿼리의 컬럼 개수는 반드시 일치해야 함.
💡 서브쿼리가 다중열이면서 다중행인 결과셋을 리턴하면 복수 레코드의 복수 필드를 한꺼번에 비교 가능
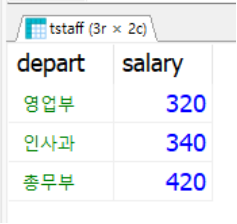
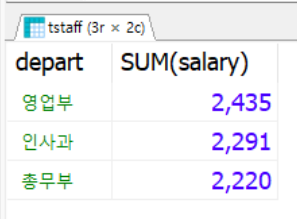
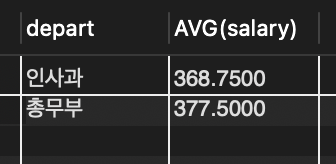
📌 부서별 최고 월급자의 목록을 조사. 여러 개의 부서가 있고 각 부서명과 최고 월급을 비교
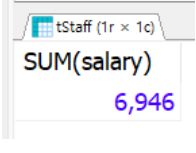
SELECT * FROM tStaff WHERE (depart, salary) IN
(SELECT depart, MAX(salary) FROM tStaff GROUP BY depart);
🔎 안쪽의 서브쿼리는 부서별로 그룹핑하여 부서명과 월급을 구함
🔎 부서별로 두개의 컬럼이 있고 그런 부서가 세 개있으니 다중열 다중행 결과셋이고 결국 하나의 테이블
📌 그룹핑할 때는 기준 필드나 집계함수만 쓸 수 있어 부서별 최고 월급까지만 조사할 수 있고 그 직원이 누구인지는 알 수 없음
➡️ 그러나 외부쿼리로 한 번 감싸 부서명과 최고 월급을 조건으로 사용하면 모든 필드 조사할 수 있음.
📌 결과셋이 다중행이므로 반드시 IN 연산자를 비교해야 함
[ 내용 참고 : IT 학원 강의 ]
'Database > MySQL' 카테고리의 다른 글
| [MySQL] 제약조건 | 식별자, 기본키, 복합키, 유니크, 체크 (1) | 2024.02.24 |
|---|---|
| [MySQL] 제약조건 | 무결성, NULL 허용, 기본값 (1) | 2024.02.24 |
| [MySQL] UPDATE 문 (1) | 2024.02.24 |
| [MySQL] DELETE 문 (1) | 2024.02.24 |
| [MySQL] INSERT 문 (0) | 2024.02.23 |