1. 무결성 관리
👩🏻💻 모든 데이터가 결함없이 완벽한 상태를 무결성 Intergrity 이라고 함
📍 시스템이 완벽해도 무결성이 깨지는 경우가 종종 발생
➡️ 실수나 에러로 잘못된 데이터를 입력할 수도 있고 불가항력적인 요인으로 멀쩡하던 데이터가 파괴되기도 함
📍 무결성이 깨지면 데이터를 사용하는 응용 프로그램도 제대로 돌아가지 x
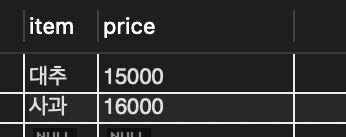
🔎 예를 들어 컴퓨터 부품을 파는 쇼핑몰의 주문 테이블을 살펴보자
// 날짜 회원 제품 개수
2020-03-04 가희원 하이넥스 메모리 DDR 64G 2
2020-03-09 나종원 엘지 그램 노트북 15 32767
2042-12-25 다민기 ATI 그래픽 카드 -8242
2020-04-01 라진규 NULL 3📍 첫 번째 레코드만 정상이고 이후의 레코드는 이상해 보임
➡️ 나종원의 노트북 32,767개는 정상 주문으로 보기 힘들고,
다민기의 경우 주문날짜도 2042년이고 주문 개수도 음수
라진규는 주문한 제품의 이름을 입력하지 않았음.
👩🏻💻 무결성이 깨지는 원인은 다양. 디스크가 기계적으로 손상되거나 네트워크의 불안정으로 데이터가 손실되는 경우, 가장 큰 원인은 사람의 실수
👩🏻💻 발생 가능한 모든 오류에 대처하는 방어 체계로 데이터를 처리하는 단계별로 서버측과 클라이언트측이 각자의 무결성 관리 정책을 제공
📍 '클라이언트측'에서는 입력할 정보에 꼭 맞는 컨트롤로 오입력을 원천 차단, 유효한 값만 서버로 보냄.
📍 '서버측'의 무결성 처리는 DBMS가 규칙을 기억하고 있다가 비정상 데이터의 입력을 거부하는 방식
[ 적용 범위에 따른 무결성 구분 ]
|
* 컬럼 무결성 컬럼 하나에 저장되는 원자적인 값을 점검하며 도메인 무결성이라고도함
➡️ 타입 지정, 널 허용 여부, 체크, 기본값 등의 제약이 있음. * 엔티티 무결성 레코드끼리 중복값을 가지지 않도록 하여 유일한 식별자를 관리. 예를 들어 주민등록번호가 같은 두 명이 존재하지 않아야 함. 기본키와 유니크 제약이 있음. * 참조 무결성 테이블간의 관계를 구성하는 키가 항상 유효하도록 관리하며 외래키 제약으로 관리. |
INSERT INTO tCity VALUES ('대구', '꽤 넓음', '200만명', 'n', '대한민국'); // 실행시 에러가 남📍 인구나 면적은 수치형이어서 123 같은 숫자만 가능하며 문자열은 저장할 수 없음. 타입이 맞더라도 지정한 길이를 초과 x
📍 타입은 물리적인 형태만 지정할 뿐 논리적인 값까지 점검하지는 못 함 ex. 음수 or 지나치게 큰 수
➡️ 논리적인 값까지 저장할 수 있는 장치가 필요. DBMS는 주로 제약을 사용
👩🏻💻 '제약 Constraint'은 조건을 위반하는 데이터를 방지하여 완결성을 보장하는 규칙
📍 제약이 없으면 무결성이 쉽게 깨짐
📍 편집창에서 필드의 입력값 형태를 미리 지정해두는 것이 바로 제약이며 이 규칙에 맞는 데이터만 입력받음
➡️ 쿼리문에서는 NULL, NOT NULL, PRIMARY KEY 같은 속성으로 제약을 지정
2. NULL 허용
👩🏻💻 NULL은 아무것도 입력되지 있지 않은 것이며 알 수 없거나 결정되지 않은 특수한 상태를 의미
👩🏻💻 필드의 NULL 허용 속성은 NULL 상태가 존재하는지를 지정
⚡️ 반드시 입력해야 하는 필수 필드는 NULL을 허용 x, 없어도 괜찮은 필드는 NULL을 허용 o
➡️ 필수 정보 : 아이디, 이름, 비밀번호, 이메일
➡️ 필수 정도 아닌 것 : 홈페이지, 주소, 전화번호
⚡️ Nullable (Null 허용), Not Nullable(Null 허용 x)
// tCity 테이블의 생성 스크립트
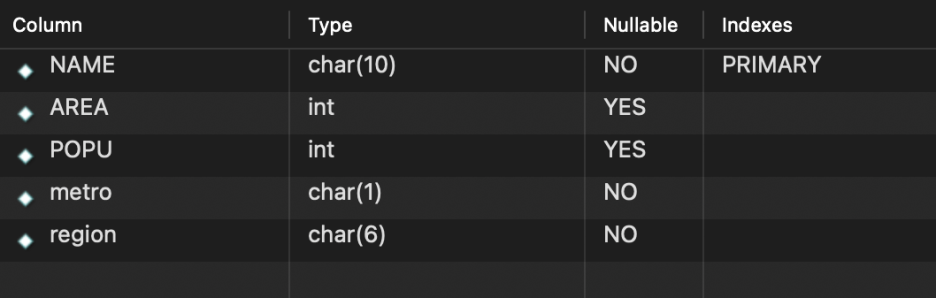
CREATE TABLE tCity (
name CHAR(10) PRIMARY KEY,
area INT NULL ,
popu INT NULL ,
metro CHAR(1) NOT NULL,
region CHAR(6) NOT NULL
);📌 name, metro, region 필드는 PRIMARY KEY 또는 NOT NULL 속성이 있어 NULL을 허용하지 않음을 지정
📌 반면 area와 pupu 필드는 NULL 속성으로 지정되어 있어 생략 가능
👩🏻💻 INSERT 명령으로 레코드를 삽입할 때 NOT NULL로 지정한 필드는 반드시 입력해여 함
➡️ 필수 정보 중 하나라도 빼 먹으면 정상적인 정보가 아니라고 판단하여 레코드 삽입을 거부
// 다음 두 쿼리문은 정상 실행.
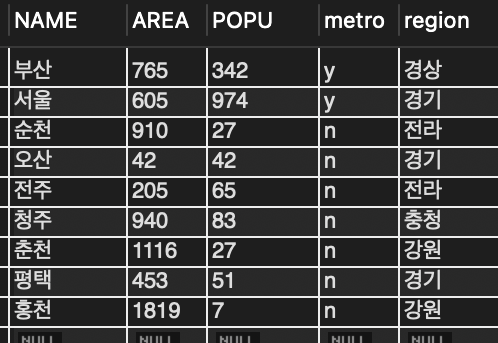
INSERT INTO tCity (name, popu, metro, region) VALUES ('울산', 114, 'y', '경상');
INSERT INTO tCity (name, metro, region) VALUES ('삼척', 'n', '강원');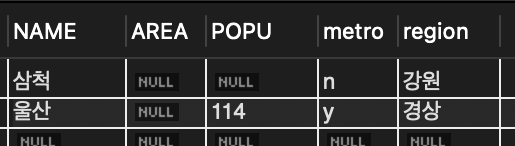
📌 울산은 면적을 모르는 상태여서 area 필드는 빼고 입력 ( 생략한 area는 NULL이 됨 )
📌 삼척은 인구, 면적을 다 생략
// 다음 두 쿼리문은 에러가 남.
INSERT INTO tCity (area, popu, metro, region) VALUES (456, 123, 'n', '충청');
INSERT INTO tCity (name, area, popu) VALUES ('의정부', 456,123);📌 충청도에 있는 어느 도시인데 이름은 없음. 필수 값이 누락되어 에러
📌 의정부는 있지만 소속과 광역시 여부가 없어 역시 무효한 정보이면 DBMS는 이런 무효한 레코드의 삽입을 거부
⚡️ NULL 허용 여부를 생략해 버리면 어떻게 될까?
CREATE TABLE tNullable (
name CHAR(10) NOT NULL,
age INT
);📌 name은 필수 필드임이 분명하나 age는 정수형이라는 것만 밝혔을 뿐 NULL 허용 여부에 대한 지정이 없음
📌 NULL 허용 여부를 생략하면 DBMS의 디폴트 허용 여부를 따른다.
INSERT INTO tNullable (name, age) values ('흥부', 36);
INSERT INTO tNullable (name) values ('놀부');
INSERT INTO tNullable (age) values (44);
📌 모든 필드값을 다 입력한 흥부는 에러 없이 입력이 된다.
📌 나이를 생략한 놀부는 DBMS의 설정에 따라 입력될 수도 있고 아닐 수도 있다.
➡️ 대부분의 DBMS는 NULL 허용이 디폴트여서 이상 없이 삽입될 확률이 높음
📌 이름을 생략하고 나이 44세만 입력하면 에러
⚡️ NULL 허용 속성은 디폴트는 DBMS마다 다르며 데이터베이스나 연결 수준에서 변경할 수도 있다.
⚡️ 그러나 설정에 영향을 받는 명령은 일관성이 없어 위험함
⚡️ 속성을 생략하지 말고 필드 선언문 끝에 항상 NULL, NOT NULL을 분명히 명시하는 것이 바람직하다.
3. 기본값
👩🏻💻 NULL 허용 속성은 데이터베이스의 성능을 저해하는 주범
➡️ 항상 NULL 상태를 감안하여 필드값이 존재하는지 점검해야 하고 보통의 값과는 다루는 방식이 달라 느릴 수 밖에 없다.
👩🏻💻 NULL 허용 대신 기본값 DEFAULT을 사용하는 것이 성능상 유리.
👩🏻💻 기본값은 필드값을 지정하지 않을 때 자동으로 입력할 값
➡️ 보통 무난한 값을 지정하는데 수치형은 0이 적당하고 문자열을 비워 두거나 'N/A'등을 많이 사용
⚡️ 도시중 광역시는 몇 개 되지 않으며 대부분 지역에 소속
⚡️ 이럴 때 metro 필드 속성에 DEFAULT 키워드와 함께 디폴트 값을 'n'으로 지정
⚡️ DEFAULT 키워드는 NULL 허용 속성보다 앞에 와야 함 (MariaDB는 순서를 강제하지 않지만 오라클은 순서를 바꾸면 에러 처리)
CREATE TABLE tCityDefault (
name CHAR(10) PRIMARY KEY,
area INT NULL ,
popu INT NULL ,
metro CHAR(1) DEFAULT 'n' NOT NULL, // 값을 괄호로 감싸 DEFAULT('n')이라고 적어도 됨
region CHAR(6) NOT NULL
);📌 새로운 레코드를 삽입할 때 metro 필드를 지정하지 않으면 자동으로 'n'을 적용
📌 기본값은 입력하지 않을 때만 적용하는 것, 값을 직접 지정하면 기본값을 무시하고 지정한 값을 적용
INSERT INTO tCityDefault (name, area, popu, region)
VALUES ('진주', 712, 34, '경상');
INSERT INTO tCityDefault (name, area, popu, metro, region)
VALUES ('인천', 1063, 295, 'y', '경기');
📌 진주시는 면적, 인구, 지역만 지정하고 광역시 여부는 생략.
➡️ 필드 목록에 metro가 아예 없는데 이 경우 디폴트가 적용되어 광역시가 아닌 것으로 삽입
📌 인천시는 모든 필드의 값을 다 제공하여 광역시로 등록
⚡️ 기본값 설정도 편집 가능해서 테이블 생성시와 달라질 수 있다.
INSERT INTO tCityDefault VALUES ('강릉', 1111, 22, '강원'); -- 에러
INSERT INTO tCityDefault VALUES ('강릉', 1111, 22, DEFAULT, '강원'); -- 정상 실행📌 필드 목록을 생략하면 값 목록이 완전해야 함
📌 metro에 기본값이 있더라도 값 목록에 이 자리는 비우면 안된다.
📌 값 목록을 완전히 적되 기본값을 적용할 필드값에 DEFAULT라고 적음. 기본값으로 변경할 때도 DEFAULT 키워드를 사용.
// 다음 명령을 인천의 metro 필드를 기본값인 'n'으로 변경.
UPDATE tCityDefault SET metro = DEFAULT WHERE name = '인천'
⚡️ 기본값의 유무와 NULL 허용 여부는 완전히 별개의 속성임을 주의
⚡️ 기본값이 지정되어 있더라도 NULL을 직접 입력할 수 있고, UPDATE 명령으로 NULL로 바꿀 수도 있음.
⚡️ 기본값은 생략시 적용할 값일 뿐이지 NULL 허용 여부까지 통제하는 것은 아님.
[ 내용 참고 : IT 학원 강의 ]
'Database > MySQL' 카테고리의 다른 글
| [MySQL] 제약조건 | 일련번호, 시퀀스, AUTO_INCREMENT (0) | 2024.02.24 |
|---|---|
| [MySQL] 제약조건 | 식별자, 기본키, 복합키, 유니크, 체크 (1) | 2024.02.24 |
| [MySQL] 서브쿼리 (SubQuery) (1) | 2024.02.24 |
| [MySQL] UPDATE 문 (1) | 2024.02.24 |
| [MySQL] DELETE 문 (1) | 2024.02.24 |