

1. 집계함수 Aggregate Function
🍋 집계 함수는 복수개의 레코드에 대해 집합적인 계산을 수행하여 합계, 평균, 분산 같은 통계값을 산출.
🍋 테이블에 저장된 정보를 함수로 전달하면 원본 데이터를 변형, 가공하여 돌려준다.
🍋 함수 호출문이 하나의 값이므로 필드 목록이나 조건절등에 값처럼 사용하면 된다.
|
함수명
|
설명
|
|
COUNT()
|
행의 개수를 센다
|
|
AVG()
|
평균을 구한다
|
|
MIN()
|
최소값을 구한다
|
|
MAX()
|
최대값을 구한다
|
|
STDEV()
|
표준편차를 구한다
|
|
VAR_SAMP()
|
분산을 구한다
|
(1) COUNT() : 행의 개수를 센다
📍 COUNT는 개수를 조사할 필드명을 전달하는데 * 지정하면 필드에 상관없이 조건에 맞는 레코드 개수를 리턴
// tStaff 테이블에 저장되어 있는 레코드 개수
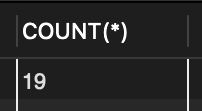
SELECT COUNT(*) FROM tStaff;
// 계산값은 열 이름이 없는데 별명을 부여하면 결과셋에 이름을 표시.
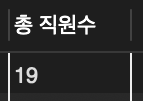
SELECT COUNT(*) AS "총 직원수" FROM tStaff;
📍 WHERE 절을 붙이면 조건에 맞는 레코드의 개수를 구한다.
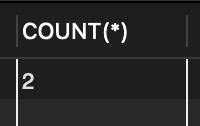
SELECT COUNT(*) FROM tStaff WHERE salary >= 400; // 월급이 400 이상인 직원의 수
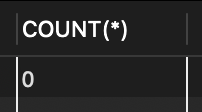
SELECT COUNT(*) FROM tStaff WHERE salary >= 10000; // 월급이 10000 이상인 직원의 수
📍 집계는 모든 레코드의 값을 참고하여 하나의 값을 구하는 것이어서 결과셋은 목록이 아닌 딱 하나의 값
➡️ 집계하는 말 자체가 다중값으로 부터 단일 값을 산출한다는 의미.
📍 조건에 맞는 레코드가 없어도 결과 값은 역시 하나
📍 특정 필드의 개수를 구할때는 인수로 필드명을 적는다.
➡️ 지정한 필드 값이 존재하는 레코드의 개수를 구함
SELECT COUNT(name) FROM tStaff;
SELECT COUNT(depart) FROM tStaff;


📍 중복 부서를 제외하고 부서의 종류가 몇 개인지 알고 싶으면 필드명 앞에 DISTINCT 키워드를 붙인다.
SELECT COUNT(DISTINCT depart) FROM tStaff;

📍 COUNT 함수는 '필드값이 제대로 들어 있는 레코드의 개수만 구하며' 필드값이 NULL인 레코드는 개수에서 제외.
📍 name이나 depart는 NULL이 없어 전체 직원수와 같지만, score 필드는 NULL 값이 있음.
SELECT COUNT(score) FROM tStaff;
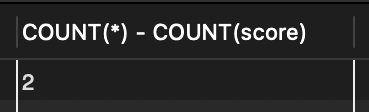
SELECT COUNT(*) - COUNT(score) FROM tStaff;
SELECT COUNT(*) FROM tStaff WHERE score IS NULL;


(2) SUM(), AVG(), MIN(), MAX()
SELECT SUM(popu), AVG(popu) FROM tCity; // 도시 목록에서 인구의 총합과 평균을 구함.
SELECT MIN(area), MAX(area) FROM tCity; // 모든 도시의 area 필드를 조사하여 가장 작은 값과 가장 큰 값을 찾음.


📍 WHERE 절을 붙이면 조건을 만족하는 레코드에 대해서만 집계를 함
SELECT SUM(score), AVG(score) FROM tStaff WHERE depart = '인사과'; // 인사과의 총 실적 합계과 평균
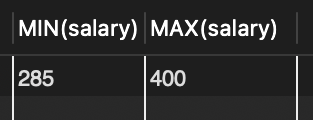
SELECT MIN(salary), MAX(salary) FROM tStaff WHERE depart = '영업부'; // 영업부에서 가장 낮는 월급과 가장 높은 월급

📍 문자열끼리는 더할 수 없어 총합을 계산할 수 없고 평균도 의미가 없다.
📍 but! 문자열이나 날짜끼리는 사전순으로 비교할 수 있고, 날짜에 대해서는 MIN, MAX 함수 사용 가능하다.
📍 집계함수와 일반필드은 같이 사용하면 안된다.
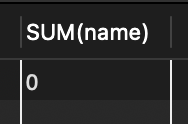
SELECT SUM(name) FROM tStaff;
SELECT MIN(name) FROM tStaff;
SELECT MAX(popu), name FROM tCity; (x)
-> SELECT popu, name FROM tCity ORDER BY popu DESC LIMIT 1;


(3) 집계 함수와 NULL
📍 NULL은 값을 알수 없는 특수한 상태로 모든 집계 함수는 NULL을 무시하고 통계를 계산한다.
📍 단, 예외적으로 레코드 개수를 세는 COUNT(*)는 NULL 도 포함하지만, 인수로 필드를 지정하면 NULL을 세지않는다.
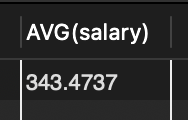
SELECT AVG(salary) FROM tStaff;
SELECT SUM(salary)/COUNT(*) FROM tStaff; // 평균은 총합을 개수로 나누어서 구함 위의 문장과 동일

📍 score의 경우에는 다른 값이 나온다.
➡️ AVG 함수는 NULL 값을 제외하고 계산을 하지만, COUNT(*)의 경우 NULL 값도 포함
➡️ 시스템 규칙에 따라 NULL이 0을 나타내는 것일 수 있음.
SELECT AVG(score) FROM tStaff;
SELECT SUM(score)/COUNT(*) FROM tStaff;
SELECT SUM(score)/COUNT(score) FROM tStaff;
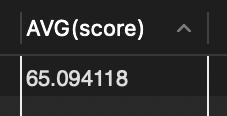
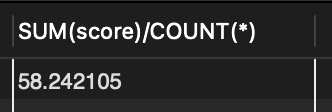

📍 COUNT(*)는 없다는 뜻의 0을 리턴, 다른 집계함수는 계산 대상이 없어서 존재하지 않는 0이 아니라 NULL을 반환
SELECT COUNT(*) FROM tStaff WHERE depart = '비서실';
SELECT MIN(salary) FROM tStaff WHERE depart = '비서실';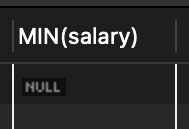
[ 내용 참고 : IT 학원 강의 ]
'Database > MySQL' 카테고리의 다른 글
| [MySQL] INSERT 문 (0) | 2024.02.23 |
|---|---|
| [MySQL] GROUP BY, HAVING (0) | 2024.02.23 |
| [MySQL] SELECT문 | ORDER BY, DISTINCT, LIMIT, OFFSET FETCH (0) | 2024.02.23 |
| [MySQL] SELECT문 | WHERE, NULL, 논리연산자, LIKE, BETWEEN, IN (0) | 2024.02.23 |
| [MySQL] SELECT문 | 기본형식, 필드목록, 별명, 계산값출력 (0) | 2024.02.23 |